La terminología es importante en la interpretación de pruebas diagnósticas. Los patólogos clínicos a menudo se centran en la precisión y exactitud de una prueba. La precisión es el grado de proximidad de la medición realizada al valor verdadero, medido por alguna alternativa”
“estándar de oro o prueba de referencia”. La precisión es la capacidad de una prueba de dar casi el mismo resultado en determinaciones repetidas.
Los médicos, por otro lado, están más preocupados por la capacidad del resultado de una prueba para discriminar entre personas con y personas sin una enfermedad o condición determinada; esta capacidad de discriminación puede caracterizarse por la sensibilidad y especificidad de una prueba. La sensibilidad es la probabilidad de que el resultado de una prueba sea positivo cuando la prueba se aplica a una persona que realmente tiene la enfermedad. La especificidad es la probabilidad de que el resultado de una prueba sea negativo cuando la prueba se aplica a una persona que en realidad no tiene la enfermedad. Una prueba perfectamente sensible puede descartar la enfermedad si el resultado es negativo. Una prueba perfectamente específica puede determinar la presencia de una enfermedad si el resultado es positivo. Dado que la mayoría de las pruebas no son ni perfectamente sensibles ni perfectamente específicas, el resultado debe interpretarse de manera probabilística en lugar de categórica. A menudo, se puede llegar a un equilibrio entre la sensibilidad y la especificidad de una prueba.
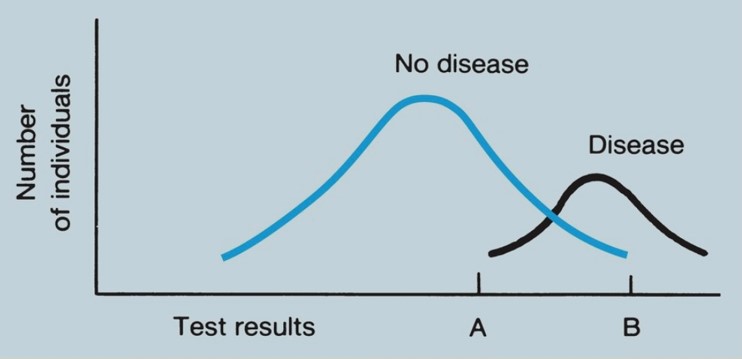
Los criterios más estrictos para hacer un diagnóstico, o comportarse como si la afección estuviera presente, tendrán una sensibilidad menor y una especificidad mayor que los criterios menos estrictos. Los ejemplos más gráficos de este principio involucran pruebas que brindan resultados cuantitativos, como la medición del antígeno prostático específico (PSA) sérico cuando se está considerando el diagnóstico de cáncer de próstata. El caso general se ilustra en la Figura 1.
=> Recibir por Whatsapp las noticias destacadas
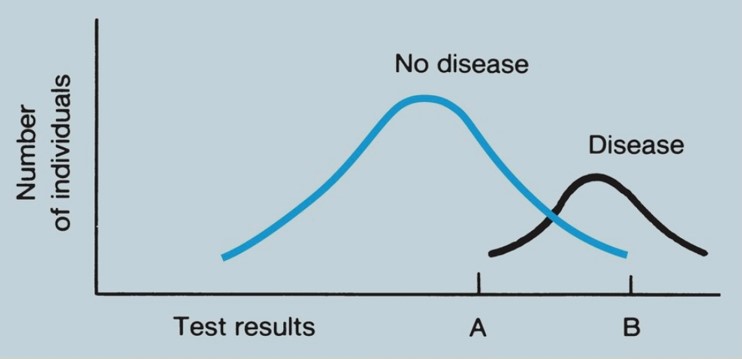
FIGURA 1. Distribución hipotética de los resultados de la prueba entre pacientes con y sin enfermedad. Debido a que las distribuciones se superponen, la prueba está lejos de ser perfecta. Si se dice que todos los pacientes con valores a la derecha de A tienen resultados «positivos», la prueba será 100% sensible pero tendrá una especificidad baja. Si se dice que solo los pacientes con valores a la derecha de B tienen resultados «positivos», la prueba será 100% específica pero tendrá una sensibilidad baja. La elección de un valor de corte entre A y B debe depender de la importancia relativa de los resultados verdaderos y falsos positivos y verdaderos y falsos negativos.
Tenga en cuenta que los valores «normales» para los resultados de la prueba se derivan con demasiada frecuencia de distribuciones de frecuencia de resultados entre personas aparentemente sanas; no se considera el posible equilibrio entre sensibilidad y especificidad. Aunque la sensibilidad y la especificidad son consideraciones importantes al seleccionar una prueba, las probabilidades que miden no son en sí mismas lo que normalmente preocupa al médico y al paciente después de que se tiene el resultado de la prueba. Ambos se ocupan de las siguientes preguntas: si el resultado es positivo, ¿cuál es la probabilidad de que la enfermedad esté presente? Si el resultado es negativo, ¿cuál es la probabilidad de que el paciente esté realmente libre de la enfermedad?
Estas probabilidades se conocen respectivamente como valor predictivo positivo y valor predictivo negativo. Se determinan no solo por la sensibilidad y la especificidad de la prueba, sino también por la probabilidad de que la enfermedad estuviera presente antes de que se solicitara la prueba. Las relaciones entre la sensibilidad y la especificidad y los valores predictivos positivos y negativos se pueden entender mejor consultando una tabla de dos por dos (Fig. 2).
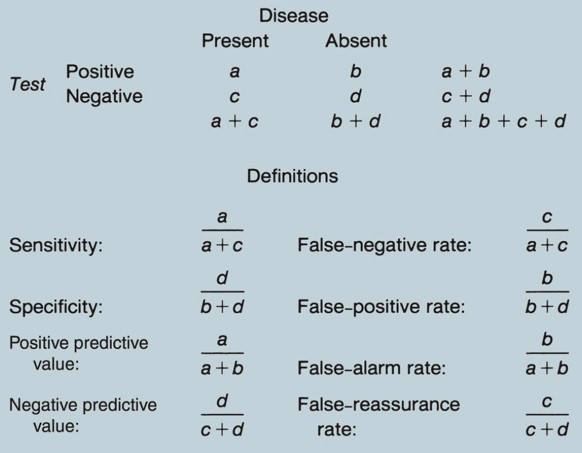
FIGURA 2 La tabla de dos por dos aclara las relaciones entre las características de la prueba (sensibilidad y especificidad) y los valores predictivos de los resultados positivos y negativos de la prueba. Los médicos que interpretan una prueba diagnóstica pueden completar la tabla si conocen la sensibilidad y la especificidad de la prueba y la probabilidad (prevalencia) de enfermedad previa a la prueba de un paciente (población).
La probabilidad previa a la prueba es a + c, y 1 − la probabilidad previa a la prueba es b + d. Multiplicar a + c por la sensibilidad proporciona el valor de a, y multiplicar b + d por la especificidad proporciona el valor de d. Los valores de la celda c y la celda b se pueden determinar mediante una simple resta. Con las celdas completadas, el valor predictivo de un resultado negativo o positivo de la prueba se puedecalcular fácilmente. Vale la pena señalar que este método de cálculo es precisamente equivalente al teorema de Bayes de probabilidad condicional
Las dos columnas indican la presencia o ausencia de enfermedad (tenga en cuenta que se supone un estándar de oro de diagnóstico) y las dos filas indican resultados de prueba positivos o negativos. Cualquier paciente dado con un resultado de prueba podría incluirse en una de las cuatro celdas etiquetadas a, b, c o d. Definiciones de sensibilidad, especificidad, valor predictivo positivo y negativo.
El valor predictivo se puede reformular utilizando estas etiquetas. Es importante tener en cuenta que cada una de estas cuatro razones tiene un complemento. El complemento de la sensibilidad (1 − sensibilidad) se conoce como la tasa de falsos negativos, mientras que el complemento de la especificidad (1 − especificidad) se conoce como la tasa de falsos positivos. “Estos términos a menudo se han utilizado de forma ambigua en la literatura médica; la tasa de falsos negativos se confunde con el complemento del valor predictivo negativo, que podría denominarse mejor tasa de falsa tranquilidad; la tasa de falsos positivos se confunde con el complemento del valor predictivo positivo, que podría denominarse mejor tasa de falsas alarmas”.
Interpretación de los resultados de las pruebas: revisión de las probabilidades diagnósticas Cuando los médicos interpretan los resultados de las pruebas, suelen procesar la información de manera informal. Rara vez se utiliza un bloc y un lápiz o una calculadora para revisar explícitamente las estimaciones de probabilidad. Sin embargo, a veces la revisión de las probabilidades diagnósticas es contraria a la intuición; por ejemplo, se ha demostrado que la mayoría de los médicos confían demasiado en los resultados positivos de las pruebas cuando la probabilidad previa a la prueba o la prevalencia de la enfermedad son bajas. Este error diagnóstico común conduce al sobrediagnóstico y a los posibles daños del sobretratamiento.
La atención a la tabla de dos por dos (fogura 2) indica por qué los valores predictivos dependen crucialmente de la prevalencia de la enfermedad. Esto es particularmente cierto cuando se utiliza una prueba para detectar una enfermedad rara. Si una enfermedad es rara, incluso una tasa de falsos positivos muy pequeña (que es, recuerde, el complemento de la especificidad) se multiplica por un número relativo muy grande, es decir, (b + d) es mucho mayor que (a + c). Por lo tanto, b será sorprendentemente grande en relación con a, y el valor predictivo positivo será contrariamente bajo. Ejemplos de este efecto son evidentes en la figura 2.
Efecto de la probabilidad previa (prevalencia) en el valor predictivo de los resultados positivos de la prueba
Considere el ejemplo de una prueba no invasiva para detectar enfermedad coronaria aplicada a un hombre de 50 años con antecedentes de dolor torácico atípico. Con base en las evaluaciones de la prueba informadas en la literatura, la sensibilidad y la especificidad de la prueba se pueden estimar en 80% y 90%, respectivamente. Con base en los síntomas y factores de riesgo, el médico estima que la probabilidad previa a la prueba del paciente de enfermedad coronaria es de 0,20. (Esto es lo mismo que decir que la prevalencia de enfermedad coronaria en una población de pacientes similares sería del 20%.) Según la Figura 3, con una probabilidad previa a la prueba de 0,20, a + c = 0,20 y b + d = 0,80. Multiplicar 0,20 por 0,8 (la sensibilidad) da un valor de 0,16 para a (la resta da un valor de 0,04 para c). Al multiplicar 0,80 por 0,9 (la especificidad), se obtiene un valor de 0,72 para d (de nuevo, la resta da 0,08 para b). El valor predictivo positivo, entonces, es 0,16/0,24, o 0,67. El valor predictivo negativo es 0,72/0,76, o 0,95.
Las frecuencias naturales se han propuesto como un enfoque más intuitivo de la siguiente manera. De 1.000 hombres con dolor torácico atípico remitidos para realizar pruebas, 200 tendrán enfermedad coronaria y de estos hombres 160 darán positivo en la prueba. De 800 hombres sin enfermedad coronaria, 80 darán positivo en la prueba, lo que revela un valor predictivo positivo de 160/240.
Los médicos pueden utilizar otro método para revisar las probabilidades rápidamente y poner a prueba su intuición. Requiere una comprensión de las probabilidades. Si p es la probabilidad de que una enfermedad en particular esté presente, la razón de p a (1 − p), o p/( 1 − p), se denomina probabilidades a favor de esa enfermedad. Las probabilidades en contra de que esa enfermedad esté presente se representan por (1 − p)/ p. Así como se puede estimar la probabilidad previa a la prueba de una enfermedad antes de que se realicen las pruebas diagnósticas, se puede expresar esa estimación como las probabilidades previas a la prueba.
Las probabilidades previas a la prueba se pueden revisar simplemente multiplicando una razón llamada razón de verosimilitud, que es la ocurrencia relativa del resultado de la prueba entre personas con y sin enfermedad, es decir, la probabilidad del resultado (ya sea positivo o negativo o un rango particular de valores) dada la presencia de la enfermedad dividida por la probabilidad de ese resultado dada la ausencia de la enfermedad.
Nótese que la razón de verosimilitud positiva no es nada más (o menos) que la razón de la sensibilidad a la tasa de falsos positivos (es decir, 1 − especificidad). La razón de verosimilitud negativa es la razón de la tasa de falsos negativos (es decir, 1 − sensibilidad) a la especificidad. Por lo tanto, las razones de verosimilitud incluyen toda la información contenida en las estimaciones de sensibilidad y especificidad. Cuando las probabilidades previas a la prueba de una enfermedad se multiplican por la razón de verosimilitud positiva, el resultado, a veces denominado probabilidades posteriores a la prueba, representa las probabilidades a favor de la enfermedad, dado el resultado de la prueba.
Volviendo al ejemplo, vemos que el paciente mencionado anteriormente con dolor torácico atípico podría tener sus probabilidades de tener enfermedad coronaria expresadas como probabilidades en lugar de como probabilidad. Una probabilidad de 0,20 es equivalente a probabilidades de 1/4 (0,20/ 0,80). La razón de verosimilitud para una prueba con una sensibilidad de 0,8 y una especificidad de 0,9 es 8 (0,8/[ 1 − 0,9]). Las probabilidades de enfermedad previas a la prueba se pueden convertir en probabilidades de enfermedad posteriores a la prueba después de un resultado positivo de la prueba simplemente multiplicándolas por la razón de probabilidad positiva: 1/4 × 8 = 2. Tenga en cuenta que la razón de probabilidades posterior a la prueba de 2:1 es equivalente a la probabilidad posterior a la prueba de 0,67.
Para algunos, es más fácil revisar las probabilidades en el entorno clínico utilizando sensibilidades y especificidades o frecuencias naturales. Para otros, es más fácil hacerlo utilizando razones de probabilidad. Un nomograma puede ser útil hasta que uno se acostumbre a convertir de probabilidades a probabilidades y viceversa (Fig. 3).
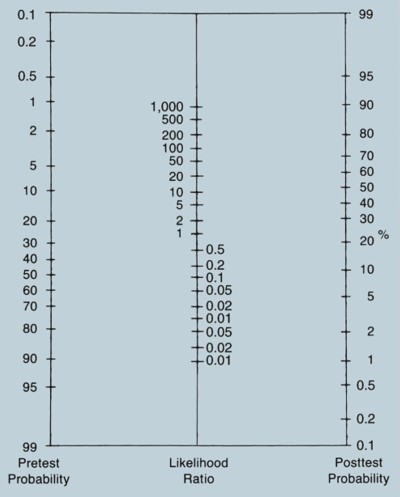
FIGURA 3. Un nomograma para aplicar cocientes de verosimilitud.