
Cuando hablamos de usar la Inteligencia Artificial en el día a día tendemos a pensar en ChatGPT y en cualquiera de los usos que podemos darle, pero el caso es que la IA es mucho más que ChatGPT, Midjourney y Runway, la IA está en todos los sectores, con modelos que van naciendo para destacarse de una u otra forma.
Hoy os voy a hablar de LLaVA, una herramienta que podéis probar en llava.hliu.cc de la siguiente forma:
- Subid una imagen en dicha web
- Haced alguna pregunta sobre la imagen
Veamos este ejemplo de una imagen que he subido, un móvil bajo la lluvia y le pregunto «Qué crees que le podría ocurrir a este móvil»
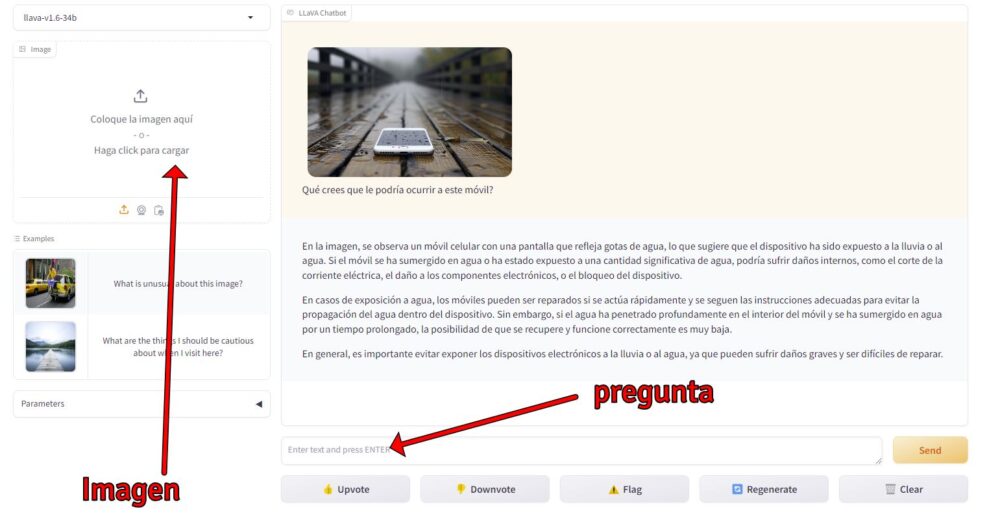
El nuevo modelo de IA de LlaVA permite ahora subir imágenes con mayor resolución, y su capacidad para interpretar el contenido es realmente sorprendente. No solo sabe lo que hay en la imagen, también es capaz de interactuar con nosotros respondiendo a nuestras preguntas en varios idiomas.
Podemos hacer una foto de algo que estamos viendo en la calle y hacer preguntas a LlaVA sobre el contexto, o integrar este sistema inteligente con nuestra aplicación, para que los usuarios tengan funciones más avanzadas.
=> Recibir por Whatsapp las noticias destacadas
Pero lo que más me llama la atención es el poder que podría tener algo así en moderación de contenido. Las redes sociales podrían descifrar perfectamente el contenido de la imagen que subimos y bloquearlo en caso de que viole sus términos de uso.
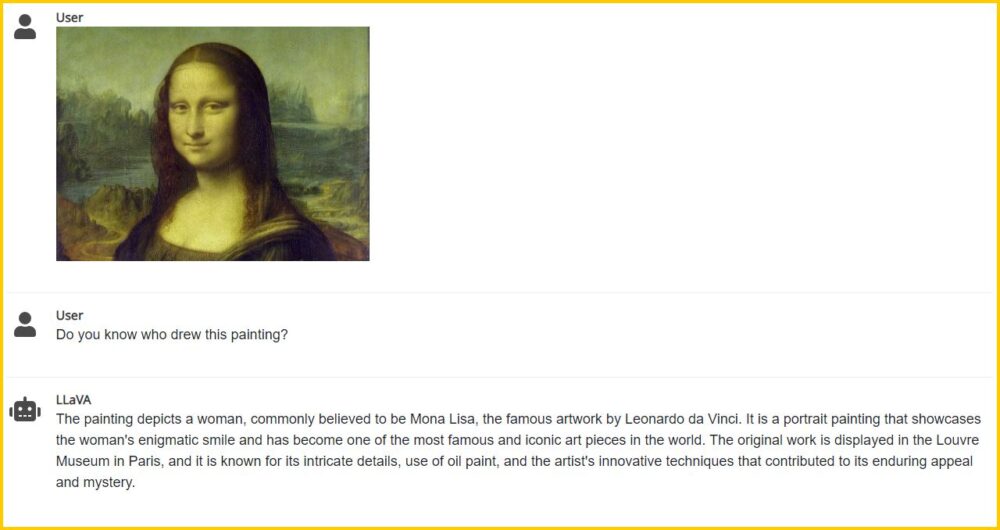
Podemos incluso subir un cuatro y preguntarle quién lo pintó:
Regístrate a la newsletter de Linkedin para recibir este tipo de contenido cada semana: click aquí
Detalles técnicos sobre LlaVA
El proyecto LLaVA (Large Language and Vision Assistant), presentado en NeurIPS 2023 como parte de una contribución oral, introduce un modelo multimodal de última generación diseñado para comprender y generar respuestas basadas tanto en texto como en imágenes. Este enfoque representa un avance significativo en el campo del procesamiento del lenguaje natural y la visión por computadora, ofreciendo capacidades de interacción visual y lingüística de propósito general. A continuación, se analizan los aspectos más destacados del proyecto, su implementación y los resultados obtenidos.
Fundamentos del proyecto LLaVA
- Colaboración Institucional: El proyecto es el resultado de una colaboración entre investigadores de la University of Wisconsin-Madison, Microsoft Research y Columbia University, destacando la importancia de la cooperación interinstitucional en el avance de la IA.
- Contribuciones Igualitarias: Haotian Liu y Chunyuan Li, entre otros, han contribuido de manera igualitaria al desarrollo de este modelo, lo que subraya el enfoque colaborativo del proyecto.
Innovaciones y implementación
- Primera Iniciativa: LLaVA marca la primera vez que se utilizan modelos de lenguaje, específicamente GPT-4, para generar datos de instrucción siguiendo instrucciones multimodales (texto e imagen), abriendo nuevas posibilidades en la instrucción automática de modelos.
- Integración de visión y lenguaje: Conecta un codificador visual pre-entrenado (CLIP ViT-L/14) y un modelo de lenguaje grande (Vicuna), utilizando una matriz de proyección simple para la alineación de características, lo que facilita un entendimiento conjunto de contenido visual y textual.
Resultados sobresalientes
LLaVA muestra capacidades de chat multimodal impresionantes, a veces exhibiendo comportamientos similares al GPT-4 multimodal en imágenes o instrucciones no vistas anteriormente, logrando un 85.1% de puntuación relativa en comparación con GPT-4. Al afinarse en preguntas y respuestas científicas, LLaVA alcanza una precisión sin precedentes del 92.53%, superando el estado del arte en este ámbito.
Datos y Open-Source
Se generaron 158K ejemplos únicos de instrucción siguiendo instrucciones multimodales basados en el conjunto de datos COCO, disponibles públicamente para la comunidad de investigación. El código, los datos generados y el modelo se han hecho públicos, promoviendo la transparencia y facilitando la reproducción y mejora por parte de la comunidad.
Conclusiones
El proyecto LLaVA no solo establece nuevos estándares de precisión en tareas específicas como el QA científico, sino que también ofrece un nuevo enfoque para el entrenamiento y la afinación de modelos multimodales. Al hacer uso eficiente de los datos públicos y lograr entrenamientos rápidos en hardware accesible (un solo nodo 8-A100), demuestra la viabilidad de modelos avanzados sin depender de conjuntos de datos de escala billonaria. Este avance subraya el potencial de los modelos multimodales en una variedad de aplicaciones, desde la interacción cotidiana hasta dominios especializados como la ciencia, y pone de relieve la importancia de la innovación continua en la intersección del procesamiento del lenguaje natural y la visión por computadora.
Referencias
Fuente: Link