
OpenAI acaba de presentar su esperado nuevo modelo, bautizado sencillamente como «o1», aunque también era ya conocido de forma coloquial como el «modelo Strawberry». Y desembarca con la promesa de abordar problemas más complejos que sus antecesores, haciendo gala de una capacidad de razonamiento avanzada.
De hecho, este modelo es el primero de una nueva serie de modelos de inteligencia artificial entrenados para simular un proceso de pensamiento similar al humano, lo que constituye un hito significativo en la evolución de los grandes modelos de lenguaje (LLMs, por sus siglas en inglés).
=> Recibir por Whatsapp las noticias destacadas
¿Qué ofrece el modelo o1?
A diferencia de sus predecesores, como GPT-4o, o1 ha sido entrenado utilizando un enfoque innovador basado en el aprendizaje por refuerzo, una técnica en la que el sistema aprende a resolver problemas recibiendo recompensas y penalizaciones por sus acciones.
Según Noam Brown, investigador de OpenAI, lo que diferencia a o1 de otros modelos es su capacidad de ‘pensar’ antes de responder. Este proceso de razonamiento, denominado ‘cadena de pensamientos’, le permite procesar consultas complejas de manera más efectiva, a medida que simula pasos intermedios para llegar a una solución.

Gracia a eso, cuenta con capacidad para resolver problemas más complejos, como tareas de programación y matemáticas avanzadas, con una precisión considerablemente mayor que sus predecesores…
…en pruebas realizadas por OpenAI, o1 demostró su capacidad para resolver el 83% de los problemas planteados en el examen clasificatorio de la Olimpiada Internacional de Matemáticas, en comparación con el 13% alcanzado por GPT-4o.
Además, en competiciones de programación como Codeforces, o1 se ubicó en el percentil 89 de los participantes, lo que reafirma su competencia en tareas técnicas.
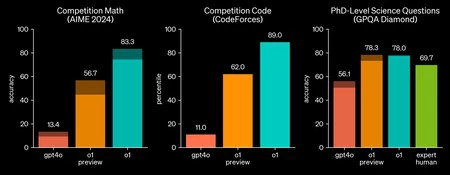
Bob McGrew, director de investigación de OpenAI, destacó que ‘o1’ está diseñado específicamente para manejar consultas que requieren razonamiento profundo, como exámenes avanzados de física y química. Según McGrew (que, recordemos, es matemático de formación),
«Este modelo es mejor que yo resolviendo el examen de matemáticas AP».
Limitaciones y retos
A pesar de los avances significativos que ofrece el modelo o1, no está exento de limitaciones. En primer lugar, en comparación con GPT-4o, o1 es más costoso y más lento… por lo que, en tareas que no requieren un razonamiento profundo, GPT-4o sigue siendo una opción más rápida y rentable.
El costo para los desarrolladores es considerable: ‘o1-preview’ cuesta $15 por cada millón de tokens de entrada y $60 por cada millón de tokens de salida, mientras que ‘GPT-4o’ tiene un precio de $5 y $15, respectivamente.
Al tratarse de un modelo incipiente, aún no dispone de muchas de las funciones que hacen útil ChatGPT, como la búsqueda de información en Internet o la carga de archivos e imágenes. También carece de características importantes en la API, como el soporte para el uso de herramientas, llamada a funciones, streaming y mensajes de sistema personalizados.
Para muchos casos comunes, GPT-4o seguirá siendo más eficiente a corto plazo
Noam Brown también ha señalado que el modelo ‘o1’ no es perfecto y, que todavía comete errores en tareas aparentemente simples, como por ejemplo a la hora de resolver el juego del ‘tres en raya’.
Además, aunque el modelo ha reducido la incidencia de las llamadas «alucinaciones» —respuestas incorrectas generadas por los modelos de lenguaje—, OpenAI admite que no ha eliminado completamente este problema.
El objetivo final de OpenAI es crear agentes autónomos, que no sólo respondan preguntas, sino que tomen acciones independientes en nombre de los usuarios. Aunque ‘o1’ aún no está listo para actuar como un agente completo, la capacidad de razonamiento que presenta es un avance crucial hacia ese objetivo.
Vía | OpenAI
Imagen | Marcos Merino mediante IA
Fuente: Link